Ưu nhược điểm của LLM - Các thuật ngữ cần biết
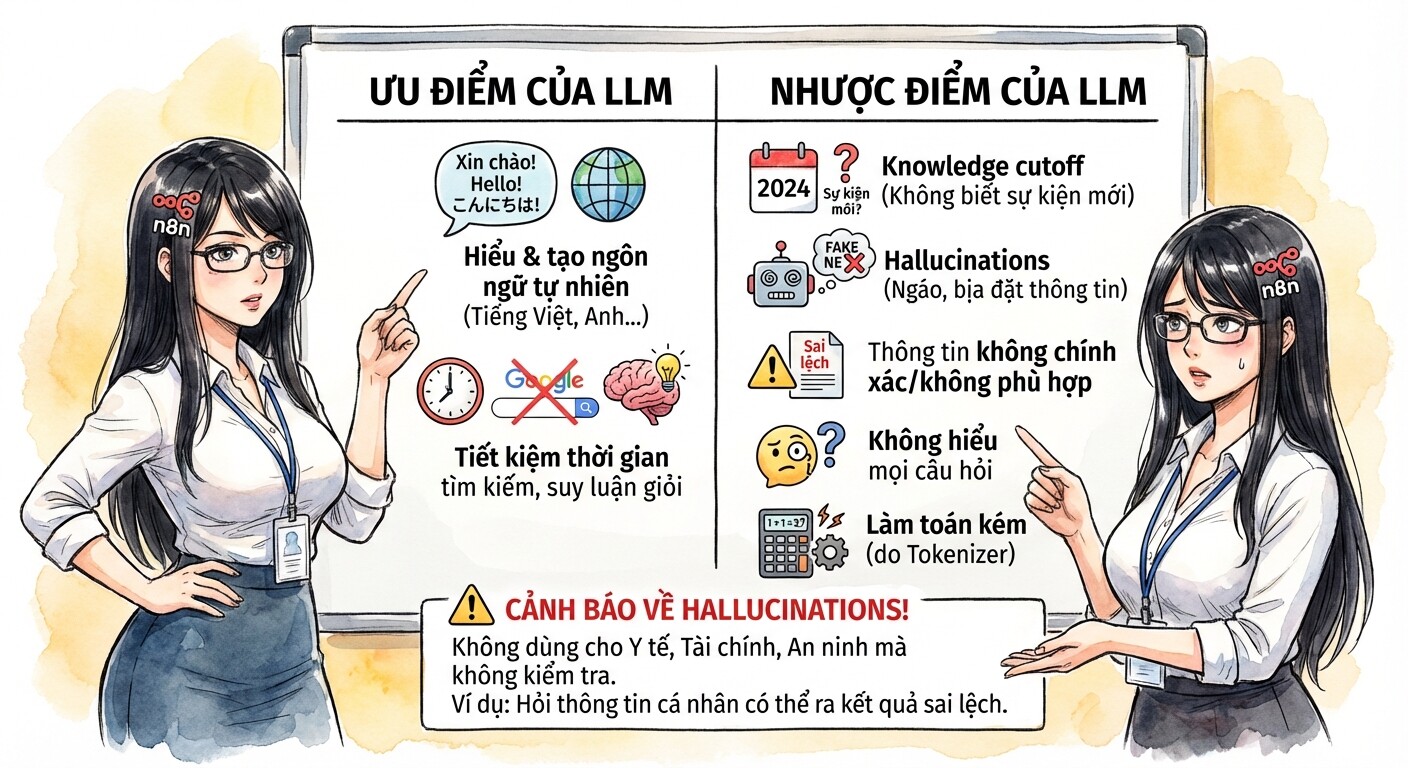
Những ưu nhược điểm của LLM
Đây là những nhược điểm của LLM mà các bạn nên chú ý:
-
Ưu điểm:
- Hiểu và tạo ra ngôn ngữ tự nhiên, với hầu hết mọi ngôn ngữ như tiếng Anh, tiếng Việt.
- Đỡ mất thời gian Google tìm kiếm dữ liệu. Các model mới và thông minh còn có thể suy luận và trả lời giỏi hơn người
-
Nhược điểm:
- Knowledge cutoff: Không thể trả lời câu hỏi ngoài kiến thức đã học. Ví dụ model được train từ dữ liệu đầu nằm 2024 sẽ không biết về những sự kiện gần nhất
- Hallucinations Bị "ngáo", do bản chất, LLM không biết câu trả lời đúng hay sai, mà sẽ... bịa ra câu trả lời nghe cho giống thực tế nhất.
- Có thể tạo ra thông tin không chính xác hoặc không phù hợp.
- Tuỳ vào độ "thông minh" của model, nó có thể không hiểu hoặc trả lời đúng với mọi câu hỏi.
- Các model này làm toán cũng khá ngu, nguyên nhân do Tokenizer.
Hallucinate - Còn gọi là "ảo tưởng" hoặc "ngáo" là một trong những nhược điểm lớn nhất của LLM. Điều này có thể dẫn đến việc tạo ra câu trả lời sai lầm hoặc không đáng tin cậy.
Vì nhược điểm này, các bạn không nên dùng LLM cho các mục đích y tế/sức khoẻ, liên quan đến tài chính hoặc an ninh nhé! Hoặc nếu có dùng thì nên có chuyên gia kiểm tra lại.
Ví dụ: Khi bạn hỏi "Anh Hoàng có account conanak99, abc123 nằm ở những forum, group nào?", một LLM có thể tự tin trả lời về thông tin... tào lao hoặc hoàn toàn sai lầm.
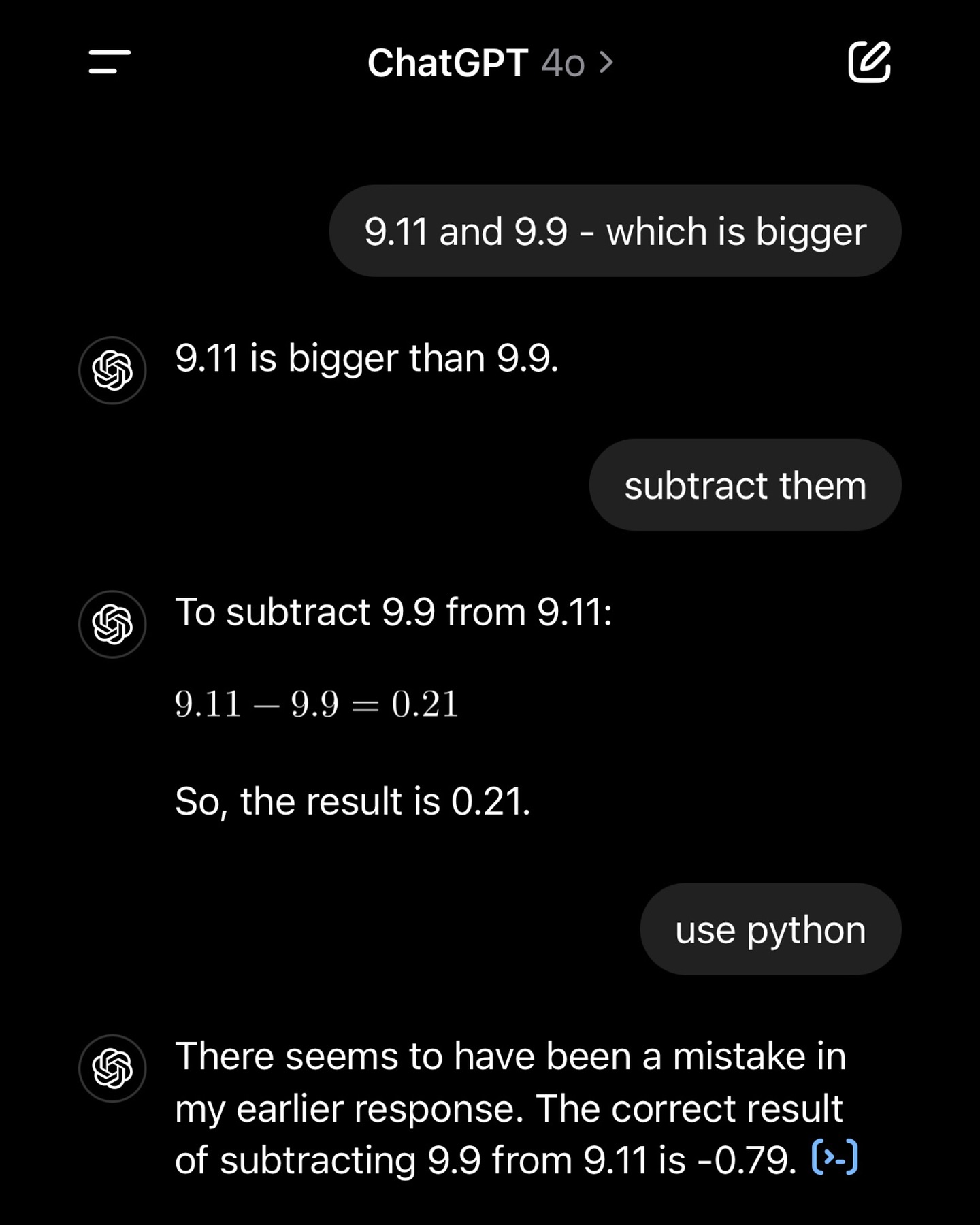
| Hallucination | Khả năng làm Toán |
|---|---|
| Các bạn lên Buôn Mê Thuột mà hỏi Hồ Xuân Hương ở đâu là dân bản địa quýnh thấy mẹ luôn! | LLM làm văn giỏi nhưng làm toán thì ngu lắm, các bạn đừng tin nhé! |
 |
 |
Giải thích một số thuật ngữ cần biết
Đây là một số thuật ngữ chính mà các bạn có thể gặp phải khi tìm hiểu về LLM:
-
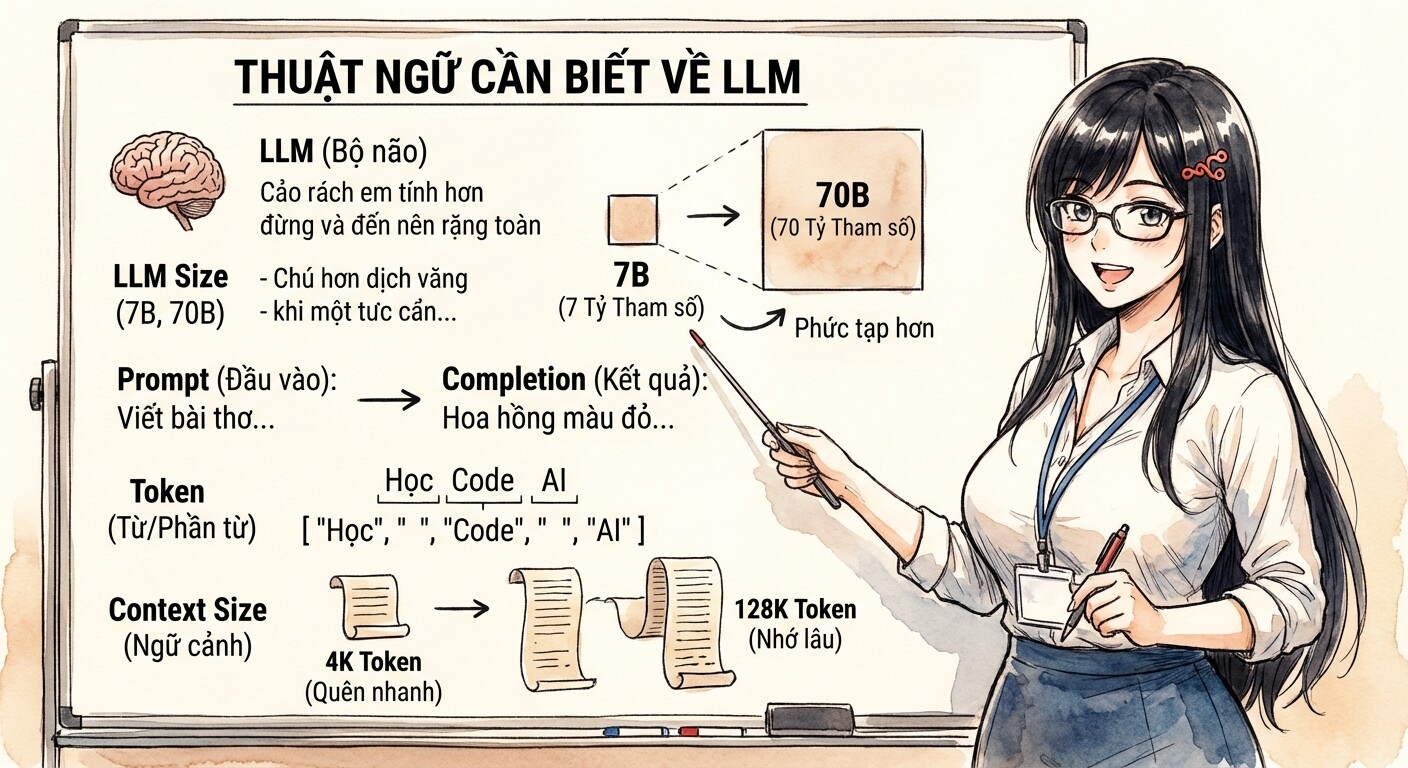
LLM: Viết tắt của Large Language Model, đây là "bộ não" của chatbot AI, hiểu và tạo ra ngôn ngữ của con người.
-
LLM Size (7B, 13B): Điều này đề cập đến số lượng tham số trong LLM, giống như dung lượng của não.
-
Blà viết tắt của tỷ. Vì vậy, mô hình 7B có 7 tỷ tham số. -
Nhìn chung, các mô hình lớn hơn có thể xử lý các tác vụ phức tạp hơn.
-
-
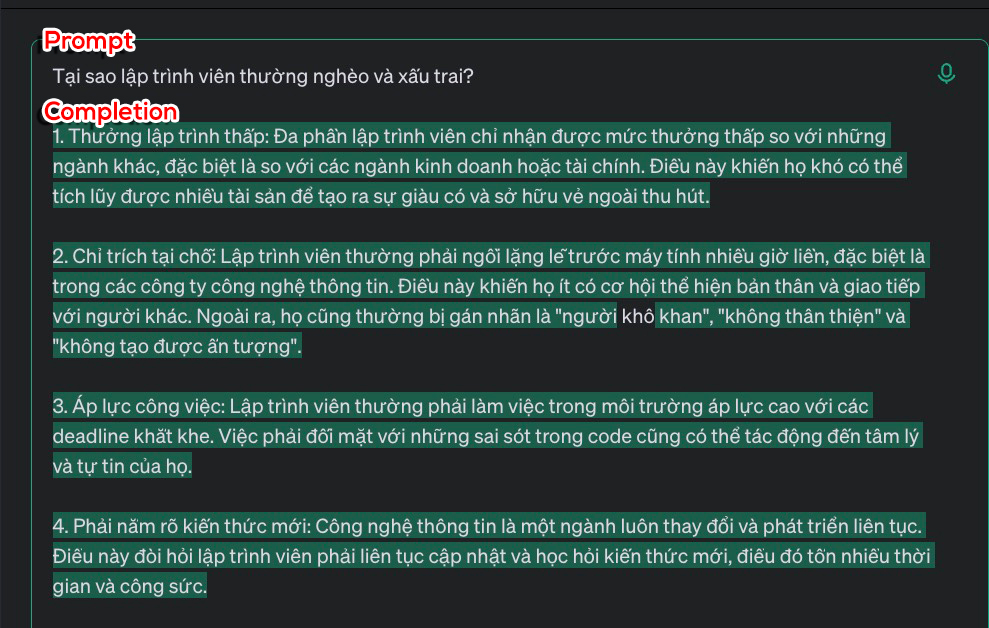
Prompt: Đây là đoạn văn bản đầu vào mà bạn cung cấp cho LLM để nó hiểu và tạo ra câu trả lời. Prompt tốt giúp LLM hiểu rõ yêu cầu của bạn và tạo ra kết quả tốt hơn.
-
Completion: Đây là kết quả mà LLM tạo ra sau khi bạn cung cấp một prompt. Nó có thể là một câu trả lời, một đoạn văn bản hoặc một đoạn code.
-
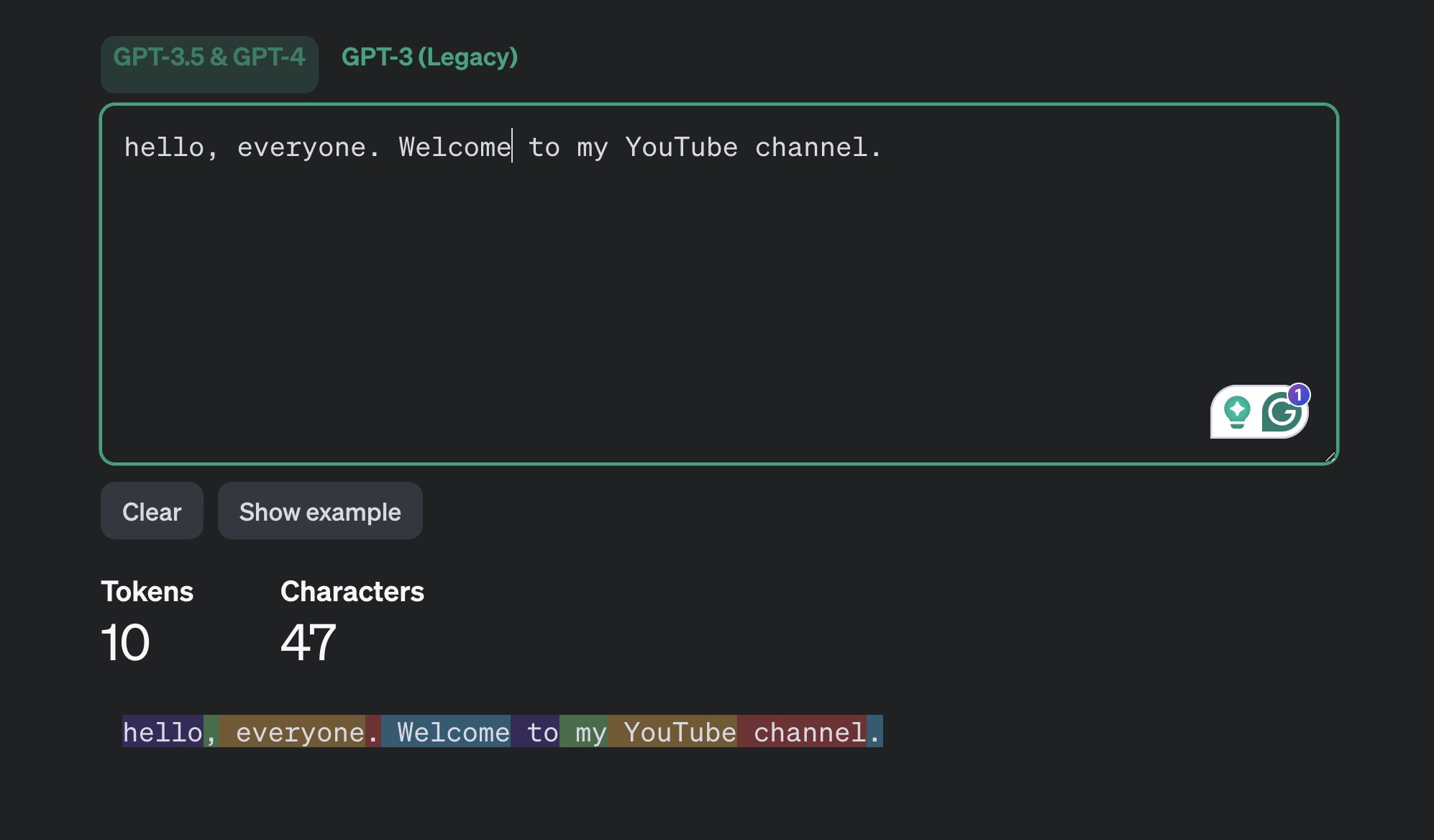
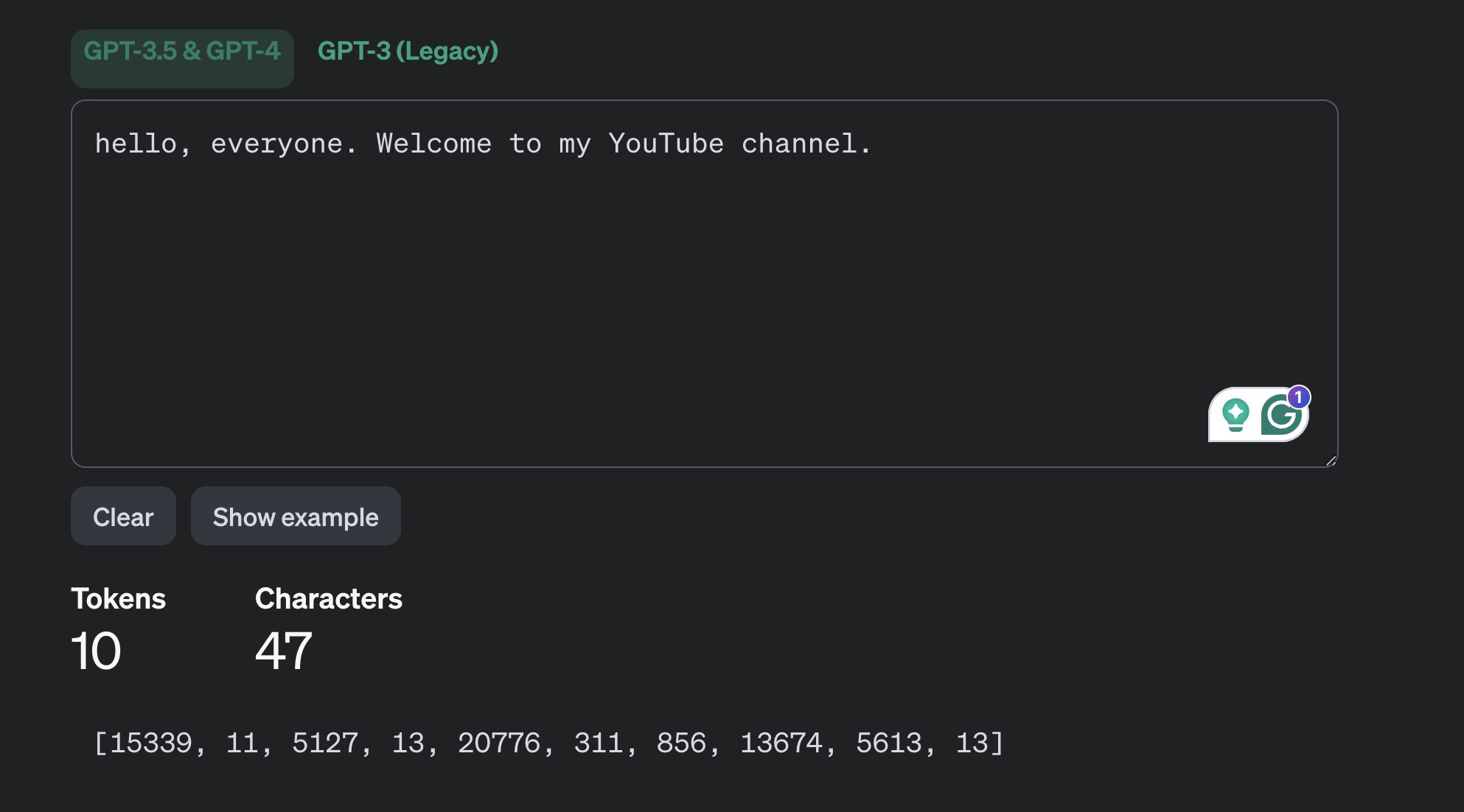
Token: Khi ta đưa
promptcho LLM xử lý, chúng ta cắt prompt ra thành nhiều token. Một token có thể là từ, một phần của từ hoặc thậm chí là các ký tự đơn lẻ.- LLM xử lý văn bản dưới dạng chuỗi token, sau đó dự đoán token tiếp theo sẽ xuất hiện.
- Bên trong dùng mấy phép toán ma trận phức tạp, bạn chưa cần quan tâm nha!)
-
Context size: Đây là số lượng token tối đa mà LLM có thể xử lý trong một đầu vào, tức là ngữ cảnh của câu hỏi.
- Ngữ cảnh lớn hơn cho phép mô hình hiểu và phản hồi với các prompt dài hơn và phức tạp hơn.
- Các phiên bản ChatGPT cũ chỉ có 4000/8000 context size, tức chúng chỉ nhớ được tầm 3000-600 từ. Do vậy, khi chat một hồi bot sẽ quên những gì bạn đã nói, vì hệ thống đã cắt bớt các chat message ở đầu cho vừa token.
- Ở các phiên bản mới, các LLM đã hỗ trợ 32k-128k token, hoặc Claude hỗ trợ 200k token, giúp bot nhớ được nhiều hơn, có thể đọc nguyên cuốn tiểu thuyết hoặc source code.
Mặc dù lý thuyết học hơi chán, nhưng hiểu các thuật ngữ và lý thuyết này sẽ giúp các bạn nắm rõ hơn cách LLM hoạt động, cũng như cách tương tác hiệu quả với AI và LLM nhé.
Lý thuyết tới đây là tạm đủ rồi! Ở những bài sau, chúng ta sẽ thực hành về viết prompt luôn!